
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- CBOW
- skip-gram
- Heap
- affine
- stak
- MySQL
- 자연어처리
- 딥러닝
- backward
- algorithm
- 프로그래머스
- 신경망
- Python
- Programmers
- Sigmoid
- DeepLearning
- kakao
- sort
- PPMI
- 파이썬
- FullyConnectedLayer
- Word2vec
- Numpy
- que
- select
- hash
- Stack
- boj
- dl
- SQL
- Today
- Total
혜온의 이것저것
[Chapter 3 word2vec] 5 word2vec 보충 / 6 정리 본문
3.5.1 CBOW 모델과 확률
A라는 현상이 일어날 확률은 P(A)라고 쓰고, 동시 확률은 P(A,B)라고 쓴다.
사후 확률은 P(A|B)로 쓴다. B가 주어졌을 때 A가 일어날 확률 이라고 해석할 수 있다.
CBOW 모델을 확률 표기법으로 기술해보자. CBOW 모델이 하는 일은 맥락을 주면 타깃 단어가 출현할 확률을 출력하는 것이다.

w_t-1과 w_t+1이 주어졌을 때 타깃이 w_t가 될 확률을 수식으로 쓰면 다음과 같다.

w_t-1과 w_t+1이 일어난 후 w_t가 일어날 확률을 뜻한다. 그리고 w_t-1과 w_t+1이 주어졌을 때 w_t가 일어날 확률로 해석할 수 있다. CBOW는 위의 식을 모델링하고 있는 것이다.
1장에서 설명한 교차 엔트로피 오차를 적용하면 다음 식을 유도해낼 수 있다.
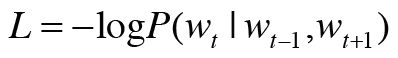
CBOW 모델의 손실 함수는 단순히 화률에 log를 취한 후 마이너스를 붙이면 된다. 이를 음의 로그 가능도라 한다.
위의 식은 샘플 데이터 하나에 대한 손실 함수이며, 이를 말뭉치 전체로 확장하면 다음 식이 된다.

CBOW 모델의 학습이 수행하는 일은 이 손실 함수의 값을 가능한 한 작게 만드는 것이다. 그리고 이 때의 가중치 매개변수가 우리가 얻고자 하는 단어의 분산 표현인 것이다. 여기에서는 윈도우 크기가 1인 경우만 생각했지만, 다른 크기라 해도 수식으로 쉽게 나타낼 수 있다.
3.5.2 skip-gram 모델
앞에서도 언급했듯이 word2vec는 2개의 모델을 제안하고 있다. 하나는 지금까지 본 CBOW 모델이고, 다른 하나는 skip-gram모델이다. skip-gram은 CBOW에서 다루는 맥락과 타깃을 역전시킨 모델이다.
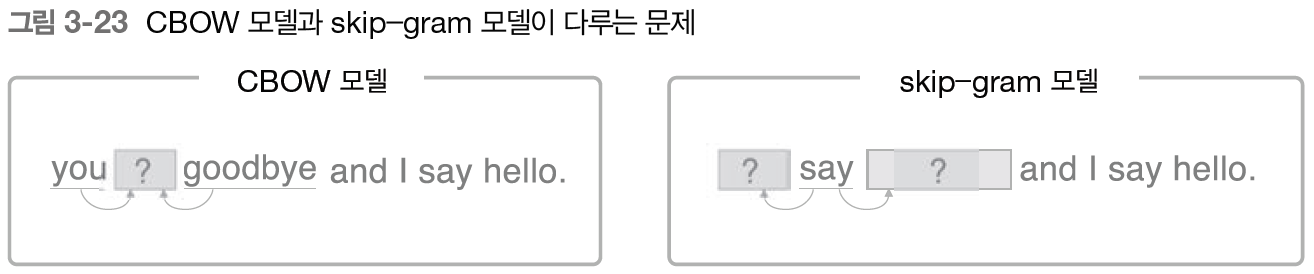
CBOW 모델은 맥락이 여러 개 있고, 그 여러 맥락으로부터 중앙의 단어를 추측한다.
한편, skip-gram 모델은 중앙의 단어로부터 주변의 여러 단어를 추측한다.
이 그림의 skip-gram 모델의 신경망 구성은 다음 그림처럼 생겼다.
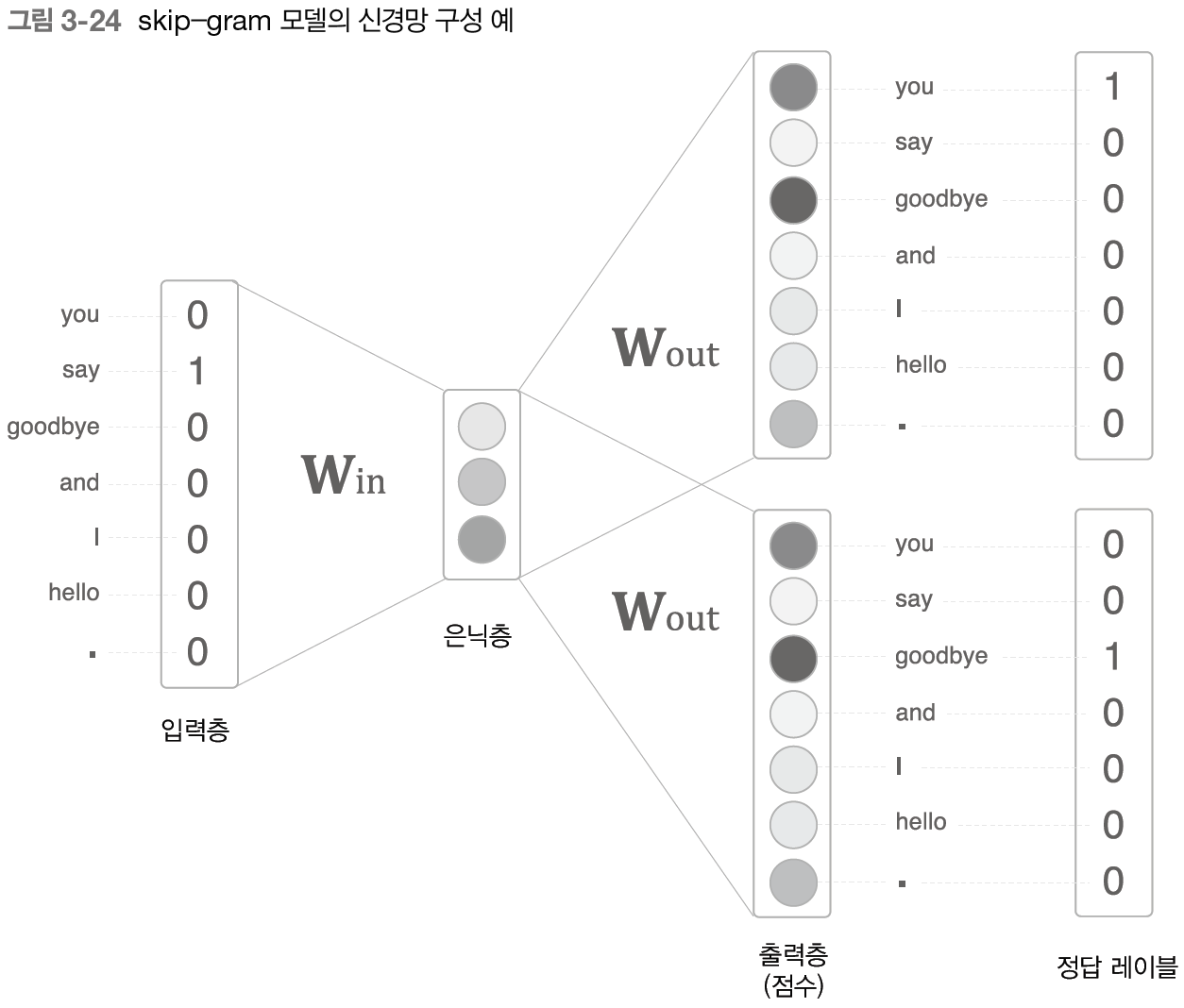
skip-gram 모델의 입력층은 하나이다. 한편 출력층은 맥락의 수만큼 존재한다.
따라서 각 출력층에서는 Softmax with Loss 계층 등을 이용해 개별적으로 손실을 구하고 이 개별 손실들을 모두 더한 값을 최종 손실로 한다.
skip-gram 모델을 확률로 표기해보자. 중앙단어 w_t로부터 맥락인 w_t-1과 w_t+1을 추측하는 경우를 생각해보자.

여기서 skip-gram 모델에서는 맥락의 단어들 사이에 관련성이 없다고 가정하고 다음과 같이 분해한다. (정확하게는 조건부 독립이라고 가정한다)

이 식을 교차 엔트로피 오차에 적용하여 skip-gram 모델의 손실 함수를 유도할 수 있다.

이 식에서 알 수 있듯이 skip-gram 모델의 손실 함수는 맥락별 손실을 구한 다음 모두 더한다.
이를 말뭉치 전체로 확장하면 skip-gram 모델의 손실함수는 다음이 된다.
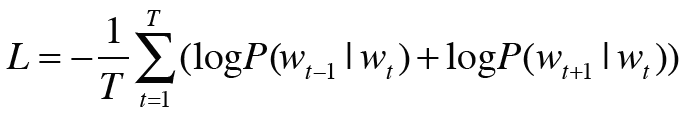
CBOW 모델의 식과 비교하면 차이가 선명해질 것이다.
CBOW 모델은 타깃 하나의 손실을 구하는 반면, skip-gram 모델은 맥락의 수만큼 추측하기 때문에 그 손실 함수는 각 맥락에서 구한 손실의 총합이어야 한다.
CBOW 모델과 skip-gram 모델 중 어느 것을 사용해야 할까?
그 대답으로는 skip-gram 모델이라고 할수 있다. 단어 분산 표현의 정밀도 면에서 skip-gram 모델의 결과가 더 좋은 경우가 많기 때문이다.
특히 말뭉치가 커질수록 저빈도 단어나 유추 문제의 성능 면에서 skip-gram모델이 더 뛰어난 경향이 있다.
반면, 학습 속도 면에서는 CBOW 모델이 더 빠르다. skip-gram 모델은 손실을 맥락의 수만큼 구해야 해서 계산 비용이 그만큼 커지기 때문이다.
CBOW 모델의 구현을 이해할 수 있다면 skip-gram 모델의 구현도 특별히 어려울 게 없다.
3.5.3 통계 기반 vs 추론 기반
지금까지 통계 기반 기법과 추론 기반 기법을 살펴봤다. 학습하는 틀 면에서 두 기법은 큰 차이가 있다. 통계 기반 기법은 말뭉치의 전체 통계로부터 1회 학습하여 단어의 분산 표현을 얻었다. 한편, 추론 기반 기법에서는 말뭉치를 일부분씩 여러 번 보면서 학습했다. 이 두 기법이 또 어떻게 다를까?
어휘에 추가할 새 단어가 생겨서 단어의 분산 표현을 갱신해야 하는 상황을 생각해보자. 통계 기반 기법에서는 계산을 처음부터 다시 해야한다. 단어의 분산 표현을 조금만 수정하고 싶어도, 동시발생 행렬을 다시 만들고 SVD를 수행하는 일련의 작업을 다시 해야 한다.
그에 반에 추론 기반 기법은 매개변수를 다시 학습할 수 있다. 지금까지 학습한 가중치를 초깃값으로 사용해 다시 학습하면 되는데, 이런 특성 덕분에 기존에 학습한 경험을 해치지 않으면서 단어의 분산 표현을 효율적으로 갱신할 수 있다.
이 점에서는 확실히 추론 기반 기법(word2vec)이 우세하다.
단어의 분산 표현의 성격이나 정밀도 면에서는 어떨까?
통계 기반 기법에서는 주로 단어의 유사성이 인코딩 된다. 한편 word2vec에서는 단어의 유사성은 물론, 한층 복잡한 단어 사이의 패턴까지도 파악되어 인코됭된다.
이런 이유로 추론 기반 기법이 통계 기반 기법보다 정확하다고 오해하곤 하지만, 실제로 단어의 유사성을 정량 평가해본 결과, 의외로 추론 기반과 통계 기반 기법의 우열을 가릴 수 없다고 한다.
추론 기반 기법과 통계 기반 기법은 서로 관련되어 있다고 한다.
구체적으로 skip-gram과 네거티브 샘플링을 이용한 모델은 모두 말뭉치 전체의 동시발생 행렬에 특수한 행렬 분해를 적용한 것과 같다. 다시 말해 두 세계는 (특정 조건 하에서) 서로 연결되어 있다고 할 수 있다.
3.6 정리
- 추론 기반 기법은 추측하는 것이 목적이며, 그 부산물로 단어의 분산 표현을 얻을 수 있다.
- word2vec은 추론 기반 기법이며, 단순한 2층 신경망이다.
- word2vec은 skip-gram모델과 CBOW 모델을 제공한다.
- CBOW 모델은 여러 단어(맥락)로부터 한나의 단어(타깃)을 추측한다.
- 반대로 skip-gram 모델은 하나의 단어(타깃)로부터 다수의 단어(맥락)를 추측한다.
- word2vec은 가중치를 다시 학습할 수 있으므로, 단어의 분산 표현 갱신이나 새로운 단어 추가를 효율적으로 수행할 수 있다.
'Deep Learning > 밑바닥부터 시작하는 딥러닝2' 카테고리의 다른 글
| [Chapter 4 word2vec 속도 개선] 1 word2vec 개선 #2 (0) | 2022.07.18 |
|---|---|
| [Chapter 4 word2vec 속도 개선] 1 word2vec 개선 #1 (0) | 2022.07.11 |
| [Chapter 3 word2vec] 4 CBOW 모델 구현 (0) | 2022.04.26 |
| [Chapter 3 word2vec] 3 학습 데이터 준비 (0) | 2022.04.26 |
| [Chapter 3 word2vec] 2 단순한 word2vec (1) | 2022.04.07 |



